Exercise: Run a cluster analysis#
You will use the skills you’ve learned throughout the course to conduct two analyses where you compute the Moran’s I statistic.
Step 1
Load the Toronto_Neighbourhoods.geojson and toronto_health_data_2017.csv files into python
Step 2 Merge the health data with the spatial data
Step 3 Generate a map of two of the three health variables included in the data set (e.g., pick diabetes and mental health, or mental health and asthma). Make sure to classify the data and make it look nice.
For each of the two columns do the following:
Step 4
Calculate a weights matrix using libpysal (referred to as lps below).
Hint The function is lps.weights.Queen.from_dataframe.
Step 5
Use the esda.Moran() function to calculate the moran’s I statistic and plot it.
Step 6
Use the esda.Moran_Local() function to calculate the LISA statistic and plot it.
Step 7 Interpret the global and local Moran’s statistics in a few sentences. What do they tell us about the spatial distribution of the two health outcomes you selected?
import numpy as np
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt
import mapclassify
import esda
import splot
import libpysal as lps
import contextily as cx
from splot.esda import moran_scatterplot
from splot.esda import lisa_cluster
#start your code here - add cells as needed
# 1) import data and clean
## Neighborhood data
nbrhd = gpd.GeoDataFrame.from_file("Toronto_Neighbourhoods.geojson")
important_spat_cols = nbrhd.columns[[4, 5, 17]]
colnames_spat = {important_spat_cols[0]: 'name',
important_spat_cols[1] : 'nbrhd_spat_id',
important_spat_cols[2] : 'geometry'}
nbrhd_simple = nbrhd.copy()
nbrhd_simple = nbrhd_simple[important_spat_cols]
nbrhd_simple.rename(columns = colnames_spat, inplace=True)
# remember to change the data type of neighbor id
nbrhd_simple["Neighbid"] = nbrhd_simple["nbrhd_spat_id"].astype(int)
nbrhd_simple.head()
| name | nbrhd_spat_id | geometry | Neighbid | |
|---|---|---|---|---|
| 0 | Casa Loma (96) | 096 | POLYGON ((-79.41469 43.67391, -79.41485 43.674... | 96 |
| 1 | Annex (95) | 095 | POLYGON ((-79.39414 43.66872, -79.39588 43.668... | 95 |
| 2 | Caledonia-Fairbank (109) | 109 | POLYGON ((-79.46021 43.68156, -79.46044 43.681... | 109 |
| 3 | Woodbine Corridor (64) | 064 | POLYGON ((-79.31485 43.66674, -79.31660 43.666... | 64 |
| 4 | Lawrence Park South (103) | 103 | POLYGON ((-79.41096 43.70408, -79.41165 43.703... | 103 |
## Health data
health = pd.read_csv('toronto_health_data_2017.csv')
health_rename_dict = {
'NeighbID': 'Neighbid',
'prev_diab_20up': 'diabetes',
'prev_asthma_0up': 'asthma',
'prev_mh_20up': 'mentalhealth'
}
health.rename(columns = health_rename_dict, inplace=True)
health.head()
| Neighbid | Name | diabetes | asthma | mentalhealth | |
|---|---|---|---|---|---|
| 0 | 1 | West Humber-Clairville | 18.2 | 15.9 | 7.2 |
| 1 | 2 | Mount Olive-Silverstone-Jamestown | 18.4 | 14.6 | 8.1 |
| 2 | 3 | Thistletown-Beaumond Heights | 17.7 | 16.0 | 8.4 |
| 3 | 4 | Rexdale-Kipling | 17.5 | 16.7 | 9.0 |
| 4 | 5 | Elms-Old Rexdale | 17.0 | 19.0 | 8.9 |
## Check the order of the neighborhood id
nbrhd_simple.sort_values(by = 'Neighbid').head()
| name | nbrhd_spat_id | geometry | Neighbid | |
|---|---|---|---|---|
| 30 | West Humber-Clairville (1) | 001 | POLYGON ((-79.55236 43.70947, -79.55238 43.709... | 1 |
| 40 | Mount Olive-Silverstone-Jamestown (2) | 002 | POLYGON ((-79.60338 43.75786, -79.60205 43.758... | 2 |
| 124 | Thistletown-Beaumond Heights (3) | 003 | POLYGON ((-79.57751 43.73384, -79.57806 43.734... | 3 |
| 122 | Rexdale-Kipling (4) | 004 | POLYGON ((-79.55512 43.71510, -79.55504 43.714... | 4 |
| 22 | Elms-Old Rexdale (5) | 005 | POLYGON ((-79.55512 43.71510, -79.55569 43.716... | 5 |
# 2) Merge health data to neighbhorhood
nbrhd_health = nbrhd_simple.merge(health, on='Neighbid')
nbrhd_health.head()
| name | nbrhd_spat_id | geometry | Neighbid | Name | diabetes | asthma | mentalhealth | |
|---|---|---|---|---|---|---|---|---|
| 0 | Casa Loma (96) | 096 | POLYGON ((-79.41469 43.67391, -79.41485 43.674... | 96 | Casa Loma | 8.1 | 13.6 | 9.3 |
| 1 | Annex (95) | 095 | POLYGON ((-79.39414 43.66872, -79.39588 43.668... | 95 | Annex | 7.4 | 12.4 | 9.7 |
| 2 | Caledonia-Fairbank (109) | 109 | POLYGON ((-79.46021 43.68156, -79.46044 43.681... | 109 | Caledonia-Fairbank | 14.3 | 16.6 | 9.8 |
| 3 | Woodbine Corridor (64) | 064 | POLYGON ((-79.31485 43.66674, -79.31660 43.666... | 64 | Woodbine Corridor | 8.9 | 14.7 | 10.3 |
| 4 | Lawrence Park South (103) | 103 | POLYGON ((-79.41096 43.70408, -79.41165 43.703... | 103 | Lawrence Park South | 6.2 | 14.7 | 8.3 |
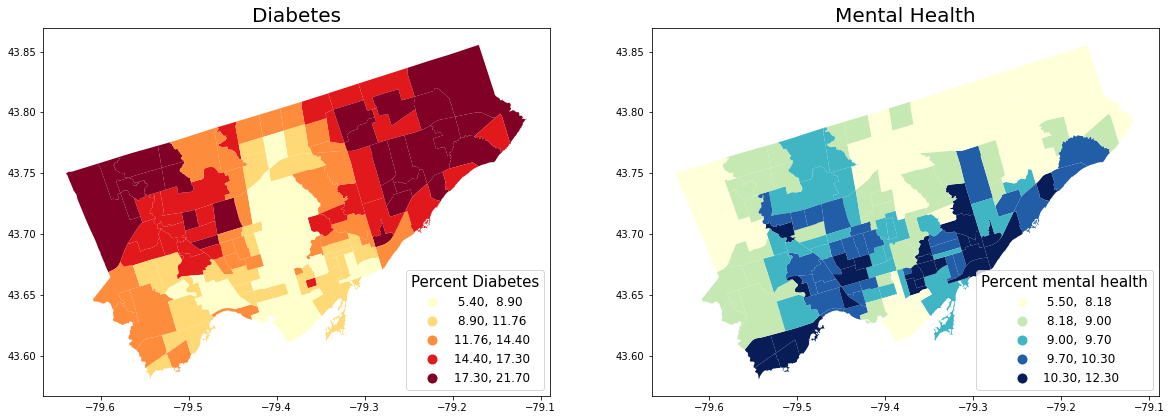
# 3) Map two health outcome variables. We pick diabetes and mentalhealth here
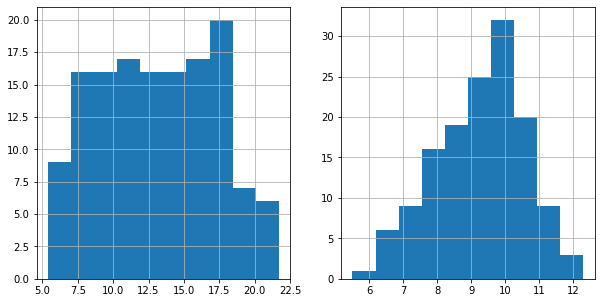
## Before mapping, it is a good idea to see the distribution of the variables
fig, axes = plt.subplots(1, 2, figsize=(10,5))
nbrhd_health.diabetes.hist(ax=axes[0], bins=10)
nbrhd_health.mentalhealth.hist(ax=axes[1], bins=10)
<AxesSubplot:>
## Map the variables in quantiles
fig, axes = plt.subplots(1, 2, figsize=(20,20))
nbrhd_health.plot(column = 'diabetes', cmap = 'YlOrRd',
scheme='quantiles',k=5, ax=axes[0],
legend=True, legend_kwds={'loc': 4, 'title': 'Percent Diabetes',
'title_fontsize': 15,'fontsize': 12})
nbrhd_health.plot(column = 'mentalhealth', cmap = 'YlGnBu', scheme='quantiles',k=5, ax=axes[1],
legend=True, legend_kwds={'loc': 4, 'title': 'Percent mental health',
'title_fontsize': 15,'fontsize': 12})
axes[0].set_title("Diabetes", fontsize = 20)
axes[1].set_title("Mental Health", fontsize = 20)
Text(0.5, 1.0, 'Mental Health')
# For each variable
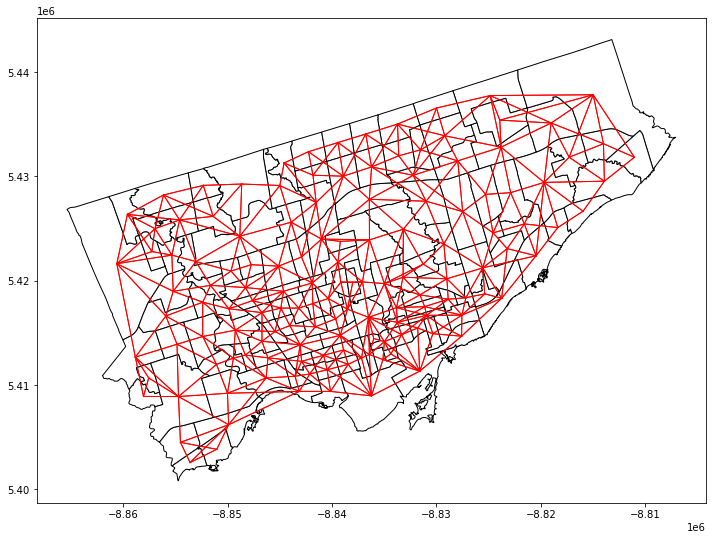
# 4) calculate a weight matrix
## Note: the weight matrix is the same for both variables
## Reproject the gdf to a projection coordinate system
nbrhd_health = nbrhd_health.to_crs("EPSG:3857")
## Create Queen's contiguity weight matrix
w = lps.weights.Queen.from_dataframe(nbrhd_health)
## Normalization
w.transform = 'R'
## Plot the contiguity matrix
fig, axes = plt.subplots(1,1, figsize = (12,12))
nbrhd_health.plot(ax = axes, edgecolor = 'black', facecolor = 'w')
w.plot(nbrhd_health, ax=axes,
edge_kws=dict(color='r', linewidth=1),
node_kws=dict(marker=''))
/var/folders/p0/ynn6kljd5pg6sh4_616yzw3c0000gn/T/ipykernel_3507/2886366439.py:9: FutureWarning: `use_index` defaults to False but will default to True in future. Set True/False directly to control this behavior and silence this warning
w = lps.weights.Queen.from_dataframe(nbrhd_health)
(<Figure size 864x864 with 1 Axes>, <AxesSubplot:>)
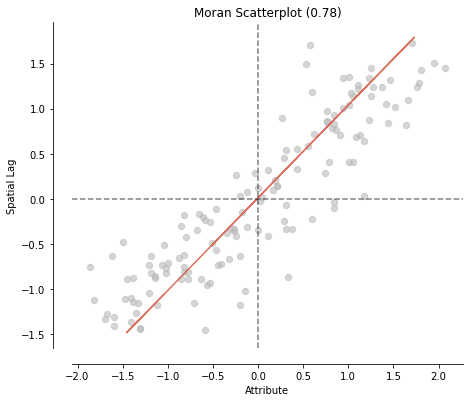
# 5) Calculate the global Moran's I and plot it
## Diabetes
mi_diabetes = esda.Moran(nbrhd_health['diabetes'], w)
print('The Morans I value is: ', mi_diabetes.I)
print('The p-value of this Morans I value is: ', mi_diabetes.p_sim)
#visualize!
splot.esda.moran_scatterplot(mi_diabetes)
The Morans I value is: 0.7810426925829449
The p-value of this Morans I value is: 0.001
(<Figure size 504x504 with 1 Axes>,
<AxesSubplot:title={'center':'Moran Scatterplot (0.78)'}, xlabel='Attribute', ylabel='Spatial Lag'>)
## Mental health
mi_mentalhealth = esda.Moran(nbrhd_health['mentalhealth'], w)
print('The Morans I value is: ', mi_mentalhealth.I)
print('The p-value of this Morans I value is: ', mi_mentalhealth.p_sim)
#visualize!
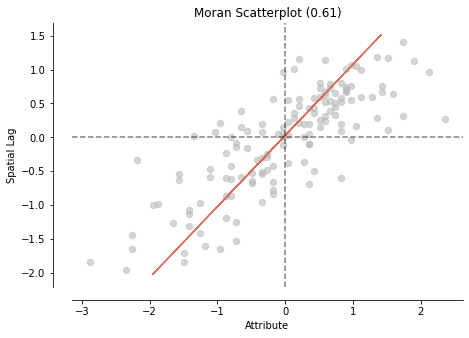
splot.esda.moran_scatterplot(mi_mentalhealth)
The Morans I value is: 0.6056281976101754
The p-value of this Morans I value is: 0.001
(<Figure size 504x504 with 1 Axes>,
<AxesSubplot:title={'center':'Moran Scatterplot (0.61)'}, xlabel='Attribute', ylabel='Spatial Lag'>)
# 6) Calculate local cluster indicator LISA
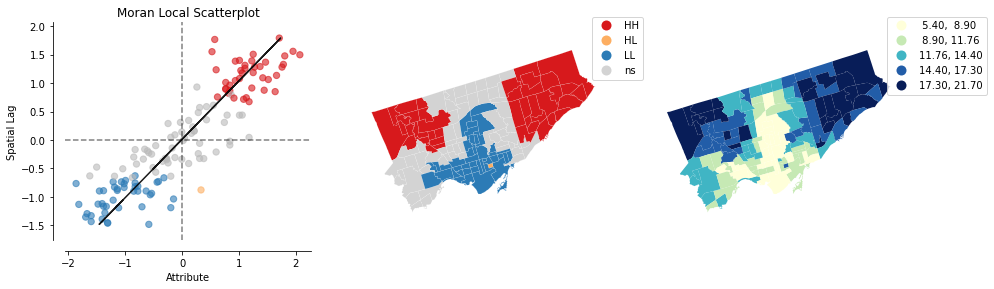
## diabetes
lisa_diabetes = esda.Moran_Local(nbrhd_health['diabetes'], w)
splot.esda.plot_local_autocorrelation(lisa_diabetes, nbrhd_health, 'diabetes')
(<Figure size 1080x288 with 3 Axes>,
array([<AxesSubplot:title={'center':'Moran Local Scatterplot'}, xlabel='Attribute', ylabel='Spatial Lag'>,
<AxesSubplot:>, <AxesSubplot:>], dtype=object))
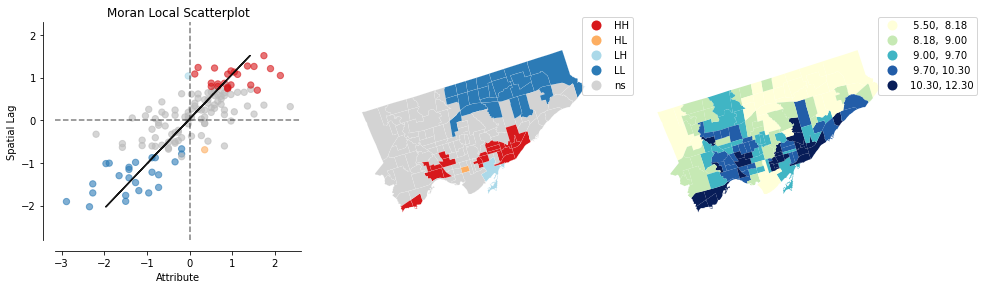
## mental health
lisa_mentalhealth = esda.Moran_Local(nbrhd_health['mentalhealth'], w)
splot.esda.plot_local_autocorrelation(lisa_mentalhealth, nbrhd_health, 'mentalhealth')
(<Figure size 1080x288 with 3 Axes>,
array([<AxesSubplot:title={'center':'Moran Local Scatterplot'}, xlabel='Attribute', ylabel='Spatial Lag'>,
<AxesSubplot:>, <AxesSubplot:>], dtype=object))
# 7) Interpretation
## Make your interpretation here!