GGR274 Lecture 3: Introduction to Programming, Part 2#
Recap#
Last lecture, we learned about:
Five basic Python data types:
Data type
Description
Example
intIntegers
10,0,-3floatNon-integer numbers
10.3,-3.5boolTrue/False
True,FalsestrText
"Y'all are cool"listA sequence of data
["Y'all", "are", "cool"]
Last lecture, we learned about:
Operations we can perform on different data types
Arithmetic:
+,-,*,/Comparison:
==,!=,<,<=,>,>=Substring search:
inIndexing:
my_string[i],my_list[i]Note: indexing starts at 0, not 1!
Last lecture, we learned about:
Functions
lentypeabssum
String methods
str.upper()str.lower()str.replace(old, new)str.split()
Learning Objectives#
Today’s lecture will be structured around the music preferences example you had in the previous lab. We will:
introduce some additional types and Python constructs as we go and
practice to integrate them in the code to achieve our goals.
So, we will cover how to:
Use new Python data type:
dictUse if statements and for loops to control how Python code gets executed
Read in data from files
define your own functions
We will also discuss how to:
“Reset” Python in your notebook
Avoid a common pitfall involving changing variables
Navigate through and find your course files on JupyterHub
Running Example: Music Preferences#
Recap:
In the cell below:
write into list
my_tasteshow much do you like the music of the following artists (let’s use -5 to +5 scale, -5 > absolutely can’t stand, 0 - idk/neutral, +5 on repeat, actually listening right now):
Drake, Tame Impala, Billie Eilish, The Weeknd, Taylor Swift
assign your name to variable
my_nameExperiment more!
Write down the same for one of your friends or family members (or make up an imaginary friend) to the list
tastes2Think how to answer based on this data:
Q1: How (comparatively) enthusiastic about music you and your friend are?
Q2: How would you approach comparing music tastes between two people?
Write down your ideas first and then you can try to put it into code (it does not have to work)!
my_tastes = [0, 0, 2, 2, 0]
friend_tastes = [3, 5, -1, -2, -3]
Q1: How (comparatively) enthusiastic about music you and your friend are?
Potential approaches:
E.g. mean of preferences:
sum(my_tastes) / len(my_tastes)
my_average = sum(my_tastes) / len(my_tastes)
friend_average = sum(friend_tastes) / len(friend_tastes)
print(f"my average is {my_average}, and my friend's average is {friend_average}")
my average is 0.8, and my friend's average is 0.4
Exercise:#
What are other potential solutions and limitations? E.g. Do we consider hating some music as being enthusiastic/passionate? How we can change our solution to account for that?
write down your idea here in plain words first the copy the code from previous cell to the next one and modify to reflect your idea. If you need some operations but don’t know how to do them yet, write in the cell above!
#code here
Now imagine we want Python to actually tell us who is more enthusiastic about music.
We are going to use one powerful Python language construct for that: If statements
If statements#
An if statement is a kind of Python code that lets us only execute some code if a specific condition is met.
# Old code so we can see all of the variables we need, no need to actually copy that
my_name = "Ilya"
my_tastes = [0, 0, 2, 2, 0]
friend_tastes = [2, 3, -1, -2, -3]
my_average = sum(my_tastes) / len(my_tastes)
friend_average = sum(friend_tastes) / len(friend_tastes)
# NEW
if my_average < 0:
print(f"Oh {my_name}, it seems like you do not like music?")
print(f"my average is {my_average}, and my friend's average is {friend_average}")
my average is 0.8, and my friend's average is -0.2
Expression inside if branch will be executed only if condition (my_average < 0) is satisfied.
Expressions outside if branch will always be executed.
Warning! Mind the indentation! This four spaces between python print(f"Oh {my_name}, it seems like you do not like music?") are important, they tell Python what is inside the if branch
if my_average < 0:
print(f"Oh {my_name}, it seems like you do not like music?")
print("Toodle-oo my friend!")
print(f"my average is {my_average}, and my friend's average is {friend_average}")
my average is 0.8, and my friend's average is -0.2
If statement terminology#
if <condition>:
<statement1>
<statement2>
...
We call the expression between the if and the colon the if condition.
We call the statements indented on the line(s) after the colon the if branch.
Repeated Warning: indentation matters! Python uses indentation to determine what code is part of an if statement vs. what’s after the if statement.
Exercise#
Change the code so that Python would tell Toodle-oo independent of my tastes:
# change the code in this cell
if my_average < 0:
print(f"Oh {my_name}, it seems like you do not like music?")
print("Toodle-oo my friend!")
print(f"my average is {my_average}, and my friend's average is {friend_average}")
my average is 0.8, and my friend's average is -0.2
if, elif, else#
We can use an optional else block after the if block to execute code only when the if condition is False.
Old code so we can see all of the variables we need. Mind you, this is a Markdown cell, so the code would not be executed and the values will come from previous cells
my_name = "Ilya"
my_tastes = [0, 0, 2, 2, 0]
friend_tastes = [2, 3, -1, -2, -3]
my_average = sum(my_tastes) / len(my_tastes)
friend_average = sum(friend_tastes) / len(friend_tastes)
if my_average < 0:
print(f"Oh {my_name}, it seems like you are not a music person?")
else:
print(f"Ah yes {my_name}, seems at least sometimes you like a good tune!")
print(f"Goodbye {my_name}, nice to meet you. :)")
Ah yes Ilya, seems at least sometimes you like a good tune!
Goodbye Ilya, nice to meet you. :)
Finally, we can include zero or more elif blocks between the if and else to express more than two cases.
my_name = "Ilya"
my_tastes = [0, 0, 2, 2, 0]
friend_tastes = [2, 3, -1, -2, -3]
my_average = sum(my_tastes) / len(my_tastes)
friend_average = sum(friend_tastes) / len(friend_tastes)
if my_average < 0:
print(f"Oh {my_name}, it seems like you are not a music person?")
elif my_average < 2:
print(f"Ah yes {my_name}, seems at least sometimes you like a good tune!")
elif my_average < 4:
print(f"Ah yes {my_name}, seems you like a good tune!")
else:
print(f"Ah yes {my_name}, great to see a music fan!")
print(f"Goodbye {my_name}, nice to meet you. :)")
Ah yes Ilya, seems at least sometimes you like a good tune!
Goodbye Ilya, nice to meet you. :)
Exercise#
Change my_average to 4. Think which branch is going to be executed. Copy the code and test yourself
#code here
Conditions are evaluated to bool! That means we can apply any operations defined for bool
my_average = 2
if my_average < 0:
print(f"Oh {my_name}, it seems like you are not a music person?")
elif my_average < 2 and my_average >= 0:
print(f"Ah yes {my_name}, seems at least sometimes you like a good tune!")
elif my_average < 4 and my_average >= 2:
print(f"Ah yes {my_name}, seems you like a good tune!")
else:
print(f"Ah yes {my_name}, great to see a music fan!")
Ah yes Ilya, seems you like a good tune!
Exercise#
my_name = "Ilya"
my_tastes = [0, 0, 2, 2, 0]
friend_tastes = [2, 3, -1, -2, -3]
my_average = sum(my_tastes) / len(my_tastes)
friend_average = sum(friend_tastes) / len(friend_tastes)
Change my_name to yours if you have not done that yet. Assign friend_name.
Define if statement printing who likes music more, you or your friend.
Back to Q2: How would you approach comparing music tastes between two people?
Spend 10 seconds to recall your ideas
It is clear that comparing average tastes does not make much sense to answer Q2. It matters who exactly do we like/dislike and how strongly, so we need to do some comparisons on the list element level.
We need a way to operate list elements!
Now, we can do
my_tastes[0]orfriend_tastes[3]like with strings but there should be a more universal way!
Operating on collection elements: For loops#
If we want to execute a piece of code once per element in a collection, we can do this using a for loop.
my_tastes = [0, 0, 2, 2, 0]
for preference in my_tastes:
print(preference)
0
0
2
2
0
For loop terminology#
for <variable> in <collection>:
<statement1>
<statement2>
...
We call
<variable>the (for) loop variable. It refers to each element of the<collection>, one at a time.We say that the for loop iterates over the
<collection>.
We call the statements indented after the colon the (for) loop body.
We call each repetition of the loop body an iteration of the loop.
Using loops: compute and print#
Problem: Add 1 to every preference value and print it
for preference in my_tastes:
print(preference + 1)
1
1
3
3
1
Using loops: compute and save#
Problem: Given a list of preferences, add 2 to every preference value and store it
To accomplish this, we will:
Create a new list variable to store the results.
In the loop body, use the (new!)
list.appendmethod to add each length to the new list.
my_tastes = [0, 0, 2, 2, 0]
my_new_kinder_tastes = []
for preference in my_tastes:
my_new_kinder_tastes.append(preference + 2)
print(my_new_kinder_tastes)
[2, 2, 4, 4, 2]
Using loops: filtering#
We can combine a for loop and an if statement to iterate over a collection, decide what to do based on whether the current value satisifies a condition.
Exercise:#
Update the code to add 3 to each preference.
Check if resulting preference is > 5. If yes, use value 5, if no, use updated value
# your code here
# Solution:
my_new_kinder_tastes = [] # cleaning up after the previous attempt
for preference in my_tastes:
new_preference = preference + 3
if new_preference > 5:
new_preference = 5
my_new_kinder_tastes.append(new_preference)
print(my_new_kinder_tastes)
[3, 3, 5, 5, 3]
Exercise:#
Given a list of artists, compute the length of each name that contains an "e", and store each result.
artists = ["Drake", "Tame Impala", "Billie Eilish", "The Weeknd", "Taylor Swift"]
lengths = []
#... your code here
Cell In[43], line 4
... your code here
^
SyntaxError: invalid syntax
#solution
for name in artists:
if "e" in name:
name_length = len(name)
lengths.append(name_length)
lengths
So, how to approach our comparison?
Remember, we have two lists and want to compare the elements somehow.
Python actually allows us to iterate through two collections (e.g. two lists) using zip function
comparison = [] for a, b in zip(list1, list2): comparison.append(a == b)
print(zip(my_tastes, friend_tastes))
print(list(zip(my_tastes, friend_tastes)))
<zip object at 0x7efcf07b4040>
[(0, 2), (0, 3), (2, -1), (2, -2), (0, -3)]
So, let’s say I want to calculate a sum of simple differences between our tastes:
differences = []
for my_pref, friend_pref in zip(my_tastes, friend_tastes):
differences.append(my_pref - friend_pref)
print(differences)
print(sum(differences))
[-2, -3, 3, 4, 3]
5
What are problems of such a measure and how to improve it?
Exercise#
Modify the code above to calculate absolute differences (ignoring the sign) and their sum
# your code
# solution
Other approaches#
E.g. treat lists as vectors and apply vector distances.similarities:
Euclidean \(d(\mathbf{a}, \mathbf{b}) = \sqrt{\sum_{i=1}^{n} (a_i - b_i)^2}\)
Functions#
note that I define my own function in the following code which we can then use as any built in function (e.g. sum, len, zip) You will get back to it later.
import math
def euclidean_distance(list1, list2):
'''
This function calculates euclidean distance between two lists.
We pass two preference lists (list1, list2) as arguments.
Note that these names work only inside our function!
The function will return a float value
'''
sum_of_squares = 0
for a, b in zip(list1, list2):
sum_of_squares = sum_of_squares + ((a - b) ** 2)
return math.sqrt(sum_of_squares) # that is what our function will return
# How to apply the new function to our data?
euclidean_distance(my_tastes, friend_tastes)
6.855654600401044
Exercise#
Create two other lists with diverging tastes and test our function. Think about edge cases
# your code here
# solution
tastes3 = [5, 5, 5, 5, 5]
tastes4 = [-5, -5, -5, -5, -5]
tastes5 = [0, 0, 0, 0, 0]
print(euclidean_distance(my_tastes, tastes3))
print(euclidean_distance(friend_tastes, tastes3))
print(euclidean_distance(my_tastes, tastes5))
print(euclidean_distance(friend_tastes, tastes5))
9.643650760992955
12.727922061357855
2.8284271247461903
5.196152422706632
Storing complex data: dictionaries (dict) and lists#
A dictionary is another type of Python collection (we already learned one - list).
Python lists are very good at storing one-dimensional data (one “column” of data).
Dictionary lets you created associated pairs of data (keys and values).
Combining lists and dictionaries we can store and process more complex data!
For example:
tastes_data = {
'Student 1': [1, -4, -5, -1, 3],
'Student 2': [2, 4, -1, 2, 0],
'Student 3': [4, 4, 3, -3, -1],
'Student 4': [-3, -4, 4, -1, 3],
'Student 5': [4, 4, -1, -4, -4],
'Student 6': [5, 5, 2, 3, -4],
'Student 7': [0, -5, 0, 4, 5],
'Student 8': [-2, -4, 2, 2, 3],
'Student 9': [-1, 4, 3, -5, -4],
'Student 10': [1, -5, 5, -5, 4],
'Student 11': [2, 5, -2, 0, -4],
'Student 12': [-2, 5, -2, -2, -3],
'Student 13': [3, 5, -4, -4, 0],
'Student 14': [3, -5, -4, -1, 3],
'Student 15': [-1, -4, 3, 0, 3]
}
type(tastes_data)
dict
I can ask to get a value from dictionary by key:
tastes_data['Student 1']
[1, -4, -5, -1, 3]
What type is the result?
type(tastes_data['Student 1'])
So no we can compare any two student tastes:
euclidean_distance(tastes_data['Student 1'], tastes_data['Student 10'])
or add new data
tastes_data['Ilya'] = my_tastes
print(tastes_data)
{'Student 1': [1, 1, -5, -1, 3], 'Student 2': [2, 1, -1, 2, 0], 'Student 3': [4, -2, 3, -3, -1], 'Student 4': [-3, -4, 4, -1, 3], 'Student 5': [4, -3, -1, -4, -4], 'Student 6': [5, 0, 2, 3, -4], 'Student 7': [0, 1, 0, 4, 5], 'Student 8': [-2, 3, 2, 2, 3], 'Student 9': [-1, -5, 3, -5, -4], 'Student 10': [1, 5, 5, -5, 4], 'Student 11': [2, 0, -2, 0, -4], 'Student 12': [-2, 4, -2, -2, -3], 'Student 13': [3, 2, -4, -4, 0], 'Student 14': [3, 2, -4, -1, 3], 'Student 15': [-1, -4, 3, 0, 3], 'Ilya': [0, 0, 2, 2, 0]}
Sometimes we need to convert between different data structures.
Let’s say we want to calculate the similarity between artists based on student preferences.
We need to reshape our data and we can use loops for that!
for student_name in tastes_data: # loops through dictionary keys
print(student_name) # prints keys (student names)
Student 1
Student 2
Student 3
Student 4
Student 5
Student 6
Student 7
Student 8
Student 9
Student 10
Student 11
Student 12
Student 13
Student 14
Student 15
for student_name in tastes_data: # loops through dictionary keys
print(tastes_data[student_name]) # but we can get a value by key!
[1, 1, -5, -1, 3]
[2, 1, -1, 2, 0]
[4, -2, 3, -3, -1]
[-3, -4, 4, -1, 3]
[4, -3, -1, -4, -4]
[5, 0, 2, 3, -4]
[0, 1, 0, 4, 5]
[-2, 3, 2, 2, 3]
[-1, -5, 3, -5, -4]
[1, 5, 5, -5, 4]
[2, 0, -2, 0, -4]
[-2, 4, -2, -2, -3]
[3, 2, -4, -4, 0]
[3, 2, -4, -1, 3]
[-1, -4, 3, 0, 3]
[0, 0, 2, 2, 0]
What shape of data do we need for artists? We are going to have one list with all artist prefs for all students (value) for each artist (key) so something like:
artist_data = {'Drake': [3, -3, ...],
'The Weekend': [1, 2, ...]}
let’s create keys with empty lists as values
artist_data = {}
for artist in artists:
artist_data[artist] = []
print(artist_data)
{'Drake': [], 'Tame Impala': [], 'Billie Eilish': [], 'The Weeknd': [], 'Taylor Swift': []}
for student_name in tastes_data: # loops through dictionary keys
student_tastes = tastes_data[student_name]
for artist, pref in zip(artists, student_tastes):
artist_data[artist].append(pref)
print(artist_data)
{'Drake': [1, 2, 4, -3, 4, 5, 0, -2, -1, 1, 2, -2, 3, 3, -1], 'Tame Impala': [-4, 4, 4, -4, 4, 5, -5, -4, 4, -5, 5, 5, 5, -5, -4], 'Billie Eilish': [-5, -1, 3, 4, -1, 2, 0, 2, 3, 5, -2, -2, -4, -4, 3], 'The Weeknd': [-1, 2, -3, -1, -4, 3, 4, 2, -5, -5, 0, -2, -4, -1, 0], 'Taylor Swift': [3, 0, -1, 3, -4, -4, 5, 3, -4, 4, -4, -3, 0, 3, 3]}
Now we can use the same euclidean distance function to calculate the similarity of artists!
euclidean_distance(artist_data['Drake'], artist_data['Taylor Swift'])
18.547236990991408
euclidean_distance(artist_data['Tame Impala'], artist_data['Billie Eilish'])
22.715633383201094
euclidean_distance(artist_data['Tame Impala'], artist_data['Taylor Swift'])
29.34280150224242
We are going to wrap up with this example here, but you are just a couple of steps from doing something cool – actually uncovering patterns in data.
See e.g. cluster dendrogram generated based on this data:
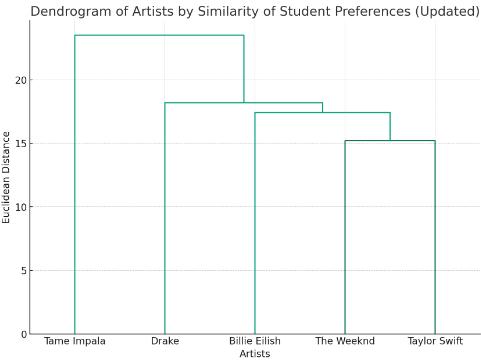
You will learn how to approach similar tasks pretty soon!
Some cool (and reasonably simple) papers doing similar things:
Preview: From lists and dictionaries to data frames (Pandas)#
Starting from the next lecture you are going to quite often work with tabular data in Pandas.
There is a special type DataFrame to represent such tabular (two-dimensional) data which is a part of pandas library.
Let us quickly explore how to convert data from basic Python to DataFrame
To use a library in Python, we need to import it into our code.
import pandas as pd
Creating your own data frame#
Some of the examples you’ll look at will involve creating small data frames “by hand”, since they’re easier to conceptualize than large data frames.
Creating a data frame manually consists of two steps.
Step 1: Create a dictionary of your data#
For us, a dictionary can map column names (strings) to column values (lists) in a table.
artist_data
{'Drake': [1, 2, 4, -3, 4, 5, 0, -2, -1, 1, 2, -2, 3, 3, -1],
'Tame Impala': [-4, 4, 4, -4, 4, 5, -5, -4, 4, -5, 5, 5, 5, -5, -4],
'Billie Eilish': [-5, -1, 3, 4, -1, 2, 0, 2, 3, 5, -2, -2, -4, -4, 3],
'The Weeknd': [-1, 2, -3, -1, -4, 3, 4, 2, -5, -5, 0, -2, -4, -1, 0],
'Taylor Swift': [3, 0, -1, 3, -4, -4, 5, 3, -4, 4, -4, -3, 0, 3, 3]}
What’s missing? Maybe we will need student names.
Let’s add them!
tastes_data
{'Student 1': [1, -4, -5, -1, 3],
'Student 2': [2, 4, -1, 2, 0],
'Student 3': [4, 4, 3, -3, -1],
'Student 4': [-3, -4, 4, -1, 3],
'Student 5': [4, 4, -1, -4, -4],
'Student 6': [5, 5, 2, 3, -4],
'Student 7': [0, -5, 0, 4, 5],
'Student 8': [-2, -4, 2, 2, 3],
'Student 9': [-1, 4, 3, -5, -4],
'Student 10': [1, -5, 5, -5, 4],
'Student 11': [2, 5, -2, 0, -4],
'Student 12': [-2, 5, -2, -2, -3],
'Student 13': [3, 5, -4, -4, 0],
'Student 14': [3, -5, -4, -1, 3],
'Student 15': [-1, -4, 3, 0, 3]}
Student names are keys, so we can just loop through them and add to a separate list:
student_names = []
for student_name in tastes_data:
student_names.append(student_name)
print(student_names)
['Student 1', 'Student 2', 'Student 3', 'Student 4', 'Student 5', 'Student 6', 'Student 7', 'Student 8', 'Student 9', 'Student 10', 'Student 11', 'Student 12', 'Student 13', 'Student 14', 'Student 15']
#now add to artist_data:
artist_data['student names'] = student_names
print(artist_data)
{'Drake': [1, 2, 4, -3, 4, 5, 0, -2, -1, 1, 2, -2, 3, 3, -1], 'Tame Impala': [-4, 4, 4, -4, 4, 5, -5, -4, 4, -5, 5, 5, 5, -5, -4], 'Billie Eilish': [-5, -1, 3, 4, -1, 2, 0, 2, 3, 5, -2, -2, -4, -4, 3], 'The Weeknd': [-1, 2, -3, -1, -4, 3, 4, 2, -5, -5, 0, -2, -4, -1, 0], 'Taylor Swift': [3, 0, -1, 3, -4, -4, 5, 3, -4, 4, -4, -3, 0, 3, 3], 'student names': ['Student 1', 'Student 2', 'Student 3', 'Student 4', 'Student 5', 'Student 6', 'Student 7', 'Student 8', 'Student 9', 'Student 10', 'Student 11', 'Student 12', 'Student 13', 'Student 14', 'Student 15']}
Step 2: Turn the dictionary into a data frame#
Now, we can turn that dictionary into a pandas DataFrame:
#remember to add import pandas as pd
import pandas as pd
my_data_frame = pd.DataFrame(artist_data)
my_data_frame
| Drake | Tame Impala | Billie Eilish | The Weeknd | Taylor Swift | student names | |
|---|---|---|---|---|---|---|
| 0 | 1 | -4 | -5 | -1 | 3 | Student 1 |
| 1 | 2 | 4 | -1 | 2 | 0 | Student 2 |
| 2 | 4 | 4 | 3 | -3 | -1 | Student 3 |
| 3 | -3 | -4 | 4 | -1 | 3 | Student 4 |
| 4 | 4 | 4 | -1 | -4 | -4 | Student 5 |
| 5 | 5 | 5 | 2 | 3 | -4 | Student 6 |
| 6 | 0 | -5 | 0 | 4 | 5 | Student 7 |
| 7 | -2 | -4 | 2 | 2 | 3 | Student 8 |
| 8 | -1 | 4 | 3 | -5 | -4 | Student 9 |
| 9 | 1 | -5 | 5 | -5 | 4 | Student 10 |
| 10 | 2 | 5 | -2 | 0 | -4 | Student 11 |
| 11 | -2 | 5 | -2 | -2 | -3 | Student 12 |
| 12 | 3 | 5 | -4 | -4 | 0 | Student 13 |
| 13 | 3 | -5 | -4 | -1 | 3 | Student 14 |
| 14 | -1 | -4 | 3 | 0 | 3 | Student 15 |
Reading data from files#
So far, we’ve been working entirely with data we defined inside our notebook.
But in practice, we’ll be reading in large quantities of data from files. Let’s learn how to do this in JupyterHub and Python and in the end we will see how to do that in pandas.
Example: Canadian Elections#
This week you will work with a small dataset of Canada’s 338 electoral districts, sourced from Elections Canada and containing the names and populations of Canada’s 338 electoral ridings.
We’ve placed a copy of this dataset in the same folder as this lab notebook (you can see this in JupyterHub by going to File -> Open).
We’ve downloaded this data in a file called ED-Canada_2016.csv and added it to course website in the same folder as this notebook.
Let’s take a look now. The easiest way to get to the file is to go to File -> Open… in the menu. Demo time!
CSV files#
ED-Canada_2016.csv is a type of file called a comma-separated values (CSV) file, which is a common way of storing tabular data.
In a CSV file:
Each line of the file represents one row
Within one line, each column entry is separated by a comma
Reading file data: open and readlines#
Now that we’ve seen the file, let’s learn how to read the file’s contents into Python.
Formally, we do this in two steps:
Open the file.
Read the file data into Python, line by line.
# Step 1
district_file = open("ED-Canada_2016.csv", encoding="utf-8")
district_file
district_data = district_file.readlines()
district_data
Data processing#
Let’s look at just the first line from the file:
district_data[0]
There’s two annoying parts about this line:
It’s a single string, but really stores two pieces of data.
There’s a strange
\nat the end of the string, representing a line break.
Goal: take the list district_data and extract just the population counts, converting to int. We’ll develop this one together!
populations = []
for line in district_data:
entries = line.split(",")
population_entry = entries[1].strip()
population_int = int(population_entry)
populations.append(population_int)
populations
Now we can compute!#
num_populations = len(populations)
total_population = sum(populations)
max_population = max(populations)
min_population = min(populations)
avg_population = total_population / num_populations
print(f"Number of population entries: {num_populations}.")
print(f"Sum of populations: {total_population}.")
print(f"Maximum district population: {max_population}.")
print(f"Minimum district population: {min_population}.")
print(f"Average district population: {avg_population}.")
Bridge to pandas#
Reading the same data in pandas usingpd.read_csv function:
district_df = pd.read_csv("ED-Canada_2016.csv", header=None)
district_df
So which way is better?
Sometimes you will work with a perfect tabular data and it is easier to ingest it straight to pandas.
But data is ~~always~~ often messy!
Reading it into python can help you to automate cleaning up or transforming it.
Strange text files or json and many other types often require changing them before you can make a perfect DataFrame
Jupyter Notebook Tips#
If Python seems to be behaving strangely or you’ve run a bunch of cells and lost track of what you’re doing, don’t panic!
Reset Python your notebook by doing the following:
Go to Kernel -> Restart & Clear Output.
Python will restart, and all cell outputs will be removed, leaving only your code.
Then, select the cell you’re currently working on, and go to Cell -> Run All Above.
Or, if you want to re-run all cells, select Cell -> Run All instead.
Common pitfall: changing variables and running cells out of order#
Demo!
my_number = 10
my_number
my_number = 20
my_number = my_number + 100
my_number
Avoiding this pitfall:
Prefer making cells “self-contained”: define and use variables in the same cell.
If you’re using a variable, make sure it’s been defined in an earlier cell.
After defining a variable, avoid changing the variable’s value in a different cell. Treat the variable as “read-only” after the cell it’s been defined in.