Class 9#
Mar. 11, 2024#
Arrangment of the last 3 tutorials#
You will conduct a communication exercise in three parts guided by your TAs.
Visualize some data and write a statement about it.
Do a short presentation.
Reflect your presentation and improve your work.
Learning objectives#
By the end of this class, you’ll be able to:
Obtain bootstrap confidence intervals;
Compare two samples using shuffling and bootstrapped resampling;
Propose hypothesis and use p-value to test hypothesis
Learn linear regression
Bootstrap - start with a story#
A data scientist is using the data in a random sample to estimate an unknown statistical parameter such as the mean time spent resting. She uses the sample to calculate the value of a statistic that she will use as her estimate.
Once she has calculated the observed value of her statistic, she could just present it as her estimate and go on her merry way. But she’s a data scientist. She knows that her random sample is just one of numerous possible random samples, and thus her estimate is just one of numerous plausible estimates.
By how much could those estimates vary? To answer this, it appears as though she needs to draw another sample from the population, and compute a new estimate based on the new sample. But she doesn’t have the resources to go back to the population and draw another sample.
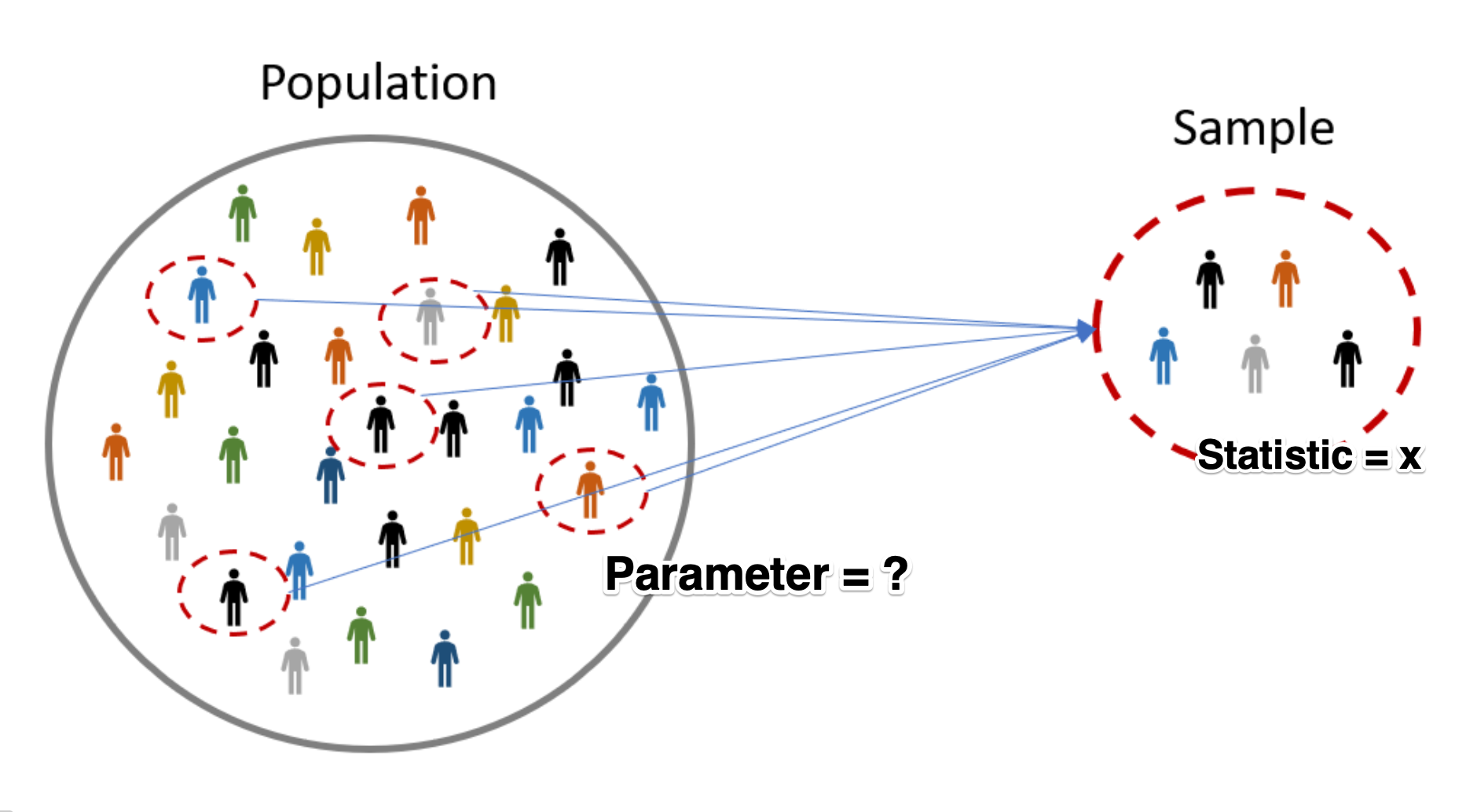
It looks as though the data scientist is stuck.
Fortunately, a brilliant idea called the bootstrap can help her out. Since it is not feasible to generate new samples from the population, the bootstrap generates new random samples by a method called resampling: the new samples are drawn at random from the original sample, instead of from the population.
We observed before that a large random sample from a population resembles the population from which it was drawn.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
time_use_df = pd.read_csv('gss_tu2016_main_file.csv')
dur01 Duration - Sleeping, resting, relaxing, sick in bed
VALUE LABEL
0 No time spent doing this activity
9996 Valid skip
9997 Don't know
9998 Refusal
9999 Not stated
Data type: numeric
Missing-data codes: 9996-9999
Record/columns: 1/65-68
time_use_df['dur01'].plot.hist(color = 'grey', edgecolor = 'black');
print(time_use_df['dur01'].median())
print(time_use_df['dur01'].mean())
time_use_df.shape
Recall what’ve done before in understanding the Laws of Average:
from ipywidgets import interact
import ipywidgets as widgets
def emp_hist_plot(n):
time_use_df['dur01'].sample(n, replace = True).plot.hist(bins=10, edgecolor="white", color="darkgrey");
interact(emp_hist_plot, n = widgets.IntSlider(min = 10, max= 5000, step=50, value=10));
In this time, we acknowledge that this dataset only has one sample of entire Canada population.
How can we get the statstics, e.g., the average sleeping time, of the entire population?
Draw a random sample with replacement of the same size (number of rows) as the original sample
This opens the possibility for the new sample to be different from the original sample.
sleep_bs_sample = time_use_df['dur01'].sample(frac = 1, replace=True)
sleep_bs_sample.plot.hist(color = 'grey', edgecolor = 'black');
print(sleep_bs_sample.median())
print(sleep_bs_sample.mean())
Why is this a good idea?#
By the law of averages, the distribution of the original sample is likely to resemble the population.
The distributions of all the “resamples” are likely to resemble the original sample.
So the distributions of all the resamples are likely to resemble the population as well.
Resampled mean#
We generated one resampled or bootstrapped mean above.
By resampling many times we can compute the empirical distribution of the mean sleep time.
The distribution of the boostrapped means should contain the population mean.
def one_bs_mean():
mean_bsample = time_use_df['dur01'].sample(frac = 1, replace=True).mean()
return mean_bsample
one_bs_mean()
Now let’s compute many resampled mean by writing a
forloop.
bootstrap_means = [] # empty list to collect means
for _ in range(5000):
bootstrap_means.append(one_bs_mean())
plt.hist(bootstrap_means, color = 'grey', edgecolor = 'black');
Boostrap confidence intervals (CIs)#
We can use the bootstrap distribution to construct a range of values such that 95% of the random samples will contain the true mean (i.e., population mean).
The range of values is called a confidence interval.
A 95% confidence interval for the mean can be constructed finding the 2.5% percentile and the 97.5% percentile.
The reason for choosing 2.5% and 97.5% is that 0.05/2 = 0.025, and 1 - 0.025 = 0.975.
We can do this using the
percentilefunction innumpy.
low_range = np.percentile(bootstrap_means, 2.5)
high_range = np.percentile(bootstrap_means, 97.5)
print(f"A 95% bootstrap confidence interval for mean is {round(low_range,2)} minutes to {round(high_range,2)} minutes.")
The choice of percentage and CIs#
Larger percentages means larger CIs: having more confidence that true value is contained in this range.
def plot_CIs(p):
plt.axvline(x = np.percentile(bootstrap_means, (100-p)/2), color = 'r', label = 'axvline - full height')
plt.axvline(x = np.percentile(bootstrap_means, p+(100-p)/2), color = 'r', label = 'axvline - full height')
plt.xlim(519, 526)
interact(plot_CIs, p = widgets.IntSlider(min = 80, max= 99, value=5));
Using Bootstrap confidence intervals to compare samples#
Do people with no children under 14 spend more time resting?#
Firstly, create a dataset (
DataFrame) with children under 14 and time spent resting.
chh0014c Child(ren) in household - 0 to 14 years
VALUE LABEL
0 None
1 One
2 Two
3 Three or more
6 Valid skip
7 Don't know
8 Refusal
9 Not stated
cols = ['dur01', 'chh0014c']
colnames = {cols[0] : 'resttime',
cols[1] : 'children'}
restchild_df = time_use_df[cols]
restchild_df = restchild_df.copy()
restchild_df.rename(columns = colnames, inplace=True)
restchild_df.head()
Hypothesis testing#
Two claims:
Null hypothesis: There is no difference in the average resting time between people with and without children under 14.
Alternative hypothesis: There is difference in the average resting time between people with and without children under 14.
2a. Alternative hypothesis: People with children under 14 have less resting time than the people with no children under 14 (preferred).
2b. Alternative hypothesis: People with children under 14 have more resting time than the people with no children under 14.
Step 1: divide the samples with two subsamples (with and without children)#
Create a new column 'Child_in_house' that indicates if a child is in the house.
restchild_df.loc[restchild_df['children'] > 0, 'Child_in_house'] = 'Yes'
restchild_df.loc[restchild_df['children'] == 0, 'Child_in_house'] = 'No'
restchild_df.head()
mean_rest_times = restchild_df.groupby('Child_in_house')['resttime'].mean()
print(mean_rest_times)
print('Mean difference:', mean_rest_times.iloc[0] - mean_rest_times.iloc[1])
restchild_df[['Child_in_house', 'resttime']].hist(by = 'Child_in_house', bins = 10, edgecolor = 'black', color = 'grey');
Step 2: Create a function to create one bootstrap sample of the mean difference.#
child = restchild_df['Child_in_house'] == 'Yes'
nochild = restchild_df['Child_in_house'] == 'No'
def bs_one_mean_diff():
# sample sleep and rest with replacement
bssample = restchild_df.sample(frac = 1, replace = True)
# compute difference in means on bootstrap sample
bs_mean_diff = (bssample.loc[nochild, 'resttime'].mean() -
bssample.loc[child, 'resttime'].mean())
return bs_mean_diff
bs_one_mean_diff()
Step 3: Compute bootstrap distribution#
bootst_mean_diffs = []
for _ in range(5000):
bootst_mean_diffs.append(bs_one_mean_diff())
plt.hist(bootst_mean_diffs, color = 'grey', edgecolor = 'black');
Step 4: obtain a 95% confidence interval for the mean difference#
np.percentile(bootst_mean_diffs, 2.5), np.percentile(bootst_mean_diffs, 97.5)
The confidence interval does not contain 0 and larger than 0.
The null hypothesis is rejected; the alternative hypothesis is accepted (in 95% CI).
The people with children have significantly less resting time than the people without children in 95% CI, thus supportting Hypothesis 2a.
In-class exercise#
Modify the code above to compute a 95% bootstrap confidence interval for the difference in 90th percentiles between respondents with and without children under 14.
Does the confidence interval contain 0?
np.percentile(bootst_mean_diffs, 5), np.percentile(bootst_mean_diffs, 95)
plt.hist(bootst_mean_diffs, color = 'grey', edgecolor = 'black')
# 95% confidence intervel in red line
plt.axvline(x = np.percentile(bootst_mean_diffs, 2.5), color = 'r', label = 'axvline - full height')
plt.axvline(x = np.percentile(bootst_mean_diffs, 97.5), color = 'r', label = 'axvline - full height')
# 90% confidence intervel in blue line
plt.axvline(x = np.percentile(bootst_mean_diffs, 5), color = 'b', label = 'axvline - full height')
plt.axvline(x = np.percentile(bootst_mean_diffs, 95), color = 'b', label = 'axvline - full height');
Larger confidence interval (95% v.s. 90%) mean wider distribution
Less likely (5% v.s. 10%) to be wrong to reject the null hypothesis
Another method to compare two samples (A review of shuffling)#
Hypothesis testing#
Two claims:
Null hypothesis: The average resting time of people with children is the same as the average resting time of people without children.
Alternative hypothesis: The average resting time of people with children is different from the average resting time of people without children.
2a. Alternative hypothesis: People with children under 14 have less resting time than the people with no children under 14.
A thought expriement: shuffling process#
Imagine we have
len(restchild_df.loc[child])cards labelledChildandlen(restchild_df.loc[nochild])cards labelledNo_child.Shuffle the cards …
Assign the cards to the samples then calculate the mean resting time difference between
ChildandNo_child. This is one simulated value of the test statistic.Shuffle the cards again …
Assign the cards to the samples then calculate the mean resting time difference between
ChildandNo_child. This is second simulated value of the test statistic.Continue shuffling, assigning , and computing the mean difference… in many times
If there is no differences of the average rest time between people with or without children (null hypothesis), the shuffling process will change the mean difference. In other words, we will observe many ‘unusual’ mean differences.
restchild_df.head()
Step 1: shuffling the children label and assignment to the samples#
shuffle_df = restchild_df.copy()
restchild_sim = shuffle_df['Child_in_house'].sample(frac=1, replace = False).reset_index(drop = True)
restchild_sim.head()
Step 2: compute the mean resting time difference between people with and without children#
mean_child = shuffle_df.loc[restchild_sim == 'Yes', 'resttime'].mean()
mean_nochild = shuffle_df.loc[restchild_sim == 'No', 'resttime'].mean()
sim_diff = mean_nochild - mean_child
sim_diff
Step 3: Repeat Steps 1 and 2 a large number of times (e.g., 5000) to get the distribution of mean differences.#
simulated_diffs = []
for _ in range(5000):
restchild_sim = shuffle_df['Child_in_house'].sample(frac=1, replace = False).reset_index(drop = True)
mean_child = shuffle_df.loc[restchild_sim == 'Yes', 'resttime'].mean()
mean_nochild = shuffle_df.loc[restchild_sim == 'No', 'resttime'].mean()
sim_diff = mean_nochild - mean_child
simulated_diffs.append(sim_diff)
import matplotlib.pyplot as plt
plt.hist(simulated_diffs, edgecolor = 'black', color = 'lightgrey');
Step 4: Compare the simulate mean differences to the observed mean difference and calculate p-value#
obs_mean_nochild = restchild_df.loc[restchild_df['Child_in_house']=='No', 'resttime'].mean()
obs_mean_child = restchild_df.loc[restchild_df['Child_in_house']=='Yes', 'resttime'].mean()
obs_diff = obs_mean_nochild - obs_mean_child
obs_diff
simulated_diffs_df = pd.DataFrame({'sim_diffs' : simulated_diffs})
numgreater = (simulated_diffs_df['sim_diffs'] >= obs_diff).sum()
print('The number of simulated differences greater than the observed difference is:', numgreater)
numsmaller = (simulated_diffs_df['sim_diffs'] < -1 * obs_diff).sum()
print('The number of simulated differences smaller than the observed difference is:', numsmaller)
pvalue = (numgreater + numsmaller)/ 5000
print('The p-value is:', pvalue)
Step 5: Interpretation#
None of the simulated differences is greater or smaller than the observed differences.
The null hypothesis is rejected.
The observed differences of resting time between people with and without children are true difference (instead of random error).
obs_diff > 0, indicating people without children have more restting time.
Think about: what is the difference between bootstrap and shuffling?#
Both bootstrap and shuffling can be applied to compare two samples, but their logics are different.
Bootstrap: resampling with replacement and get the distribution of mean differences, which represents the mean differences in population
bssample = restchild_df.sample(frac = 1, replace = True)
Shuffling: shuffle the label (reampling without replacement) and reassign to the samples to get the distribution of mean differences, which represents the “unusual” values
restchild_sim = shuffle_df['Child_in_house'].sample(frac=1, replace = False).reset_index(drop = True)
Bootstrap can be applied to many other situations in order to obtain robust results (e.g., regression), while shuffling can only applied in comparison between samples.
Linear Regression#
Basic idea#
Linear regression is a useful technique for creating models to explain (linear) relationships between variables.
For use in multiple regression, the dependent variable must be numeric and have meaningful numeric values (i.e., must be an interval variable).
The independent variables can be categorical or interval variables.
Example 1: perfect linear relationship between dependent and independent variables#
Data#
import pandas as pd
import numpy as np
data = {'depvar' : np.arange(start = 0, stop = 8, step =1),
'indvar' : np.arange(start = 0, stop = 8, step =1)}
df = pd.DataFrame(data)
df
Plot the data#
import matplotlib.pyplot as plt
plt.scatter(x = df['indvar'], y = df['depvar'])
plt.xlabel('indvar')
plt.ylabel('depvar');
The scatter plot shows each pair of points (1, 1), (2, 2), etc.
'indvar'is sometimes called a predictor variable or covariate, and'depvar'is called the dependent variable.The dependent variable is predicted exactly by the independent variable.
Compute the regression line#
from statsmodels.formula.api import ols
regmod = ols('depvar ~ indvar', data = df) # setup the model
The code above uses the
olsfunction fromstatsmodels.formula.apiThe syntax in the function
olsfunction'depvar ~ indvar'is a special syntax for describing statistical models.The column name to the left of
~specifies the dependent variable.The column name to the right of
~specifies the independent variable(s).
regmod_fit = regmod.fit() # estimate/fit the model
After the model is setup then the fit function can be applied to the model. This function computes the equation of the regression line.
regmod_fit.params # get parameter estimates
The estimates of the y-intercept and slope are labelled
Intercept(1.11e-16 approx 0) andindvar(1.00e+00 approx 1).This means the regression equation is: $\(\texttt{depvar} = 0 + 1 \times \texttt{indvar}\)$
Example 2: another perfect linear relationship#
data = {'depvar' : np.arange(start = 0, stop = 8, step =1) + 2,
'indvar' : np.arange(start = 0, stop = 8, step =1)}
df = pd.DataFrame(data)
df
plt.scatter(x = df['indvar'], y = df['depvar'])
plt.ylim([0, 10])
plt.xlabel('indvar')
plt.ylabel('depvar');
regmod = ols('depvar ~ indvar', data = df) # setup the model
regmod_fit = regmod.fit() # estimate/fit the model
regmod_fit.params # get parameter estimates
The scatter plot is similar to Example 1 except that the values of the dependent variable has been increased by 2.
The equation of the regression line for this data is: $\(\texttt{depvar} = 2 + 1 \times \texttt{indvar} \)$
Interpretation of y-intercept#
When the independent variable is 0 the dependent variable is 2. This is the meaning of the y-intercept value of 2.
Interpretation of slope#
For a one-unit change in the independent variable the dependent variable changes by 1 unit.
Example 3: close to linear#
Examples 1 and 2 were perfect linear relationships.
In this example we examine what happens if the relationship between the dependent and independent variables is almost linear.
np.random.seed(11) #set the seed so that it's reproducible
data = {'depvar' : np.arange(start = 0, stop = 8, step =1) + 2,
'indvar' : np.arange(start = 0, stop = 8, step =1) + np.random.uniform(low = 0, high = 2, size = 8)}
df = pd.DataFrame(data)
df
plt.scatter(x = df['indvar'], y = df['depvar'])
plt.ylim([0, 10])
plt.xlabel('indvar')
plt.ylabel('depvar');
regmod = ols('depvar ~ indvar', data = df) # setup the model
regmod_fit = regmod.fit() # estimate/fit the model
regmod_fit.params # get parameter estimates
So, now the relationship isn’t perfectly linear, but close. The equation of this regression line is:
import seaborn as sns
sns.regplot(x = 'indvar', y = 'depvar', data = df, ci = None);
The regplot function in the seaborn library will produce a scatter plot with the regression line.
The parameters of regplot
xis the independent variable.yis the dependent variable.ci = Nonespecifies no confidence interval for the regression line
Statistical summary of linear regression#
import warnings
warnings.filterwarnings('ignore') # turn off warnings
regsum = regmod_fit.summary()
A statistical summary of the regression model is given above using the
summaryfunction instatsmodels.There are three summary tables, but we will only be interested in the second summary table—
regsum.tables[1](in this course).
regsum.tables[1]
What does the statistical summary represent?
the column labelled
coefare same values asregmod_fit.params. In this case the average increasedepvarfor a one unit change inindvaris 0.9229.
the
std errcolumn represents the standard deviation of the intercept and slope (we won’t discuss in this course).
the
tcolumn represents the value of the t-statistic (we won’t discuss in this course).
regsum.tables[1]
the column
P>|t|represents the p-value corresponding to the null hypothesis that the intercept or slope are equal to 0. If the value is small then this is evidence against the null hypothesis. But if the p-value is large then there is no evidence against the null hypothesis.
Currently, how small a p-value should be to provide evidence against a null hypothesis is being debated. Although, the traditional threshold is 0.05 (i.e., a p-value less than or equal to 0.05 is supposed to indicate evidence against the null hypothesis).
In the example above the p-value for the slope is 0. This indicates strong evidence that the true value of the slope is non-zero.
The columns
[0.025 0.975]form a plausible range of values for the y-intercept and slope (formally known as a 95% confidence interval). In this case the plausible values for the slope are 0.745 and 1.101. If the plausible range includes 0 then this is usually interpreted as not providing evidence against the null hypothesis.
Predicted values and residuals#
If the values of the independent variable are plugged into the regression equation then we obtain the fitted values.
df
The fitted value for the first row of df is (when indvar == 0.360539) :
1.6254 + 0.9229*0.360539
To extract the fitted values from a regression model use the fittedvalues function in statsmodels.
regmod_fit.fittedvalues
If the linear regression model is used on an independent variable that is not in the data set used to build the model then it’s often referred to as a predicted value.
new_indvar = pd.DataFrame(data = {'indvar':[10,11,12,13]})
regmod_fit.predict(new_indvar['indvar'])
The residual is the dependent variable minus the fitted value.
df.head(2)
regmod_fit.fittedvalues.head(2)
So, for the first row the residual is:
2 - 1.9581414431
To extract the residuals from a regression model use the resid function in statsmodels.
regmod_fit.resid
If the linear regression model fits the data well then the residuals should be close to 0.
One indication that the linear regression model fits well is to examine the diagnostic scatter plot of residuals versus fitted values.
A plot that looks like a random scatter of points around 0 indicates that linear regression is an appropriate model.
Since there are only 8 points it’s hard to spot a pattern.
plt.scatter(regmod_fit.fittedvalues, regmod_fit.resid)
plt.axhline(y = 0)
plt.xlabel('fitted values')
plt.ylabel('residuals')
Accuracy of linear regression#
There are several measures of accuracy for linear regression.
One popular measure is R-squared, representing how much the dependent variable are explained by the independent variable(s).
R-squared can be calculated from a fitted model regression model using the
rsquaredfunction instatsmodels.R-squared is always between 0 and 1.
R-squared of 0 indicates a poor fit
R-squared of 1 indicates a perfect fit
regmod_fit.rsquared
Example 4: regression with two or more independent variables#
It’s possible to include more than one independent variable in a regression model.
np.random.seed(11) #set the seed so that it's reproducible
data = {'depvar' : np.arange(start = 0, stop = 8, step =1) + 2,
'indvar1' : np.arange(start = 0, stop = 8, step =1) + np.random.uniform(low = 0, high = 2, size = 8),
'indvar2' : np.arange(start = 0, stop = 8, step =1) + np.random.normal(loc = 0, scale = 1, size = 8)}
df = pd.DataFrame(data)
df
To include more than one independent variable in a regression model add it to the right side of syntax for describing statistical models.
'depvar ~ indvar1 + indvar2'
regmod = ols('depvar ~ indvar1 + indvar2', data = df) # setup the model
Now fit regmod.
regmod_fit = regmod.fit() # estimate/fit the model
Extract the regression parameter estimates using params.
regmod_fit.params # get parameter estimates
The estimated linear (multiple) linear regression model is:
The y-intercept value (1.892482) is the value of the dependent variable when
indvar1andindvar2are both 0.If
indvar1changes by one-unit,depvarchanges (on average) by 0.549341 (whenindvar2remains the same).If
indvar2changes by one-unit,depvarchanges (on average) by 0.385197 (whenindvar1remains the same).
Statistical summary of a multiple regression model#
multregsummary = regmod_fit.summary()
multregsummary.tables[1]
The statistical summary indicates:
the p-value for
indvar1is 0.003 and the range of plausible values for the slope is 0.288 to 0.810.the p-value for
indvar2is 0.010 and the range of plausible values for the slope is 0.137 to 0.634.Since, both p-values are small there is evidence that slope is different from 0, and the range of plausible values does not include 0.
Accuracy of multiple regression model#
regmod_fit.rsquared
plt.scatter(regmod_fit.fittedvalues, regmod_fit.resid)
plt.axhline(y = 0)
plt.xlabel('fitted values')
plt.ylabel('residuals')
Questions?
What is the effect of recent immigration on asthma rates in Toronto neighbourhoods?#
Data#
Data from http://torontohealthprofiles.ca contains data on asthma and immigration for each neighbourhood in Toronto.
Sociodemographic data#
Read sociodemographic data from the excel file
1_socdem_neighb_2006-2.xlswith sheet namesocdem_2006intopandasusingread_excel.
fname = '1_socdem_neighb_2006-2.xls'
sname = 'socdem_2006'
socdem_neighb = pd.read_excel(fname, sheet_name = sname, header = 10) # the table starts in row #11
socdem_neighb.head()
Which column should we select to measure immigration? There are several choices.
socdem_neighb.columns
Let’s use
'% Recent immigrants-within 5 years'to represent recent immigrants in a neighborhood.Later on we will want a few more sociodemographic columns, so let’s create a new
DataFrameand rename the columns.
cols = ['Neighbourhood id', 'Neighbourhood Name',
'Median household income after-tax $ ‡',
'% Rented Dwellings', '% Unemployment rate *',
'% Recent immigrants-within 5 years', '% Visible minority']
socdem_neighb = socdem_neighb[cols]
colnames = {cols[0] : 'Neighbid',
cols[1] : 'name',
cols[2] : 'median_income',
cols[3] : 'rented_dwell',
cols[4] : 'unemployment',
cols[5] : 'immigration5',
cols[6] : 'vismin'}
socdem_neighb = socdem_neighb.copy()
socdem_neighb.rename(columns = colnames, inplace = True)
socdem_neighb.head()
Asthma data#
Read data from the excel file
1_ahd_neighb_db_ast_hbp_mhv_copd_2007.xlswith sheet name1_ahd_neighb_asthma_2007intopandasusingread_excel.
fname = '1_ahd_neighb_db_ast_hbp_mhv_copd_2007.xls'
sname = '1_ahd_neighb_asthma_2007'
asthma_neighb = pd.read_excel(fname, sheet_name = sname, header = 11) #the table starts with row #12
asthma_neighb.head()
The asthma rates are broken down by sex and age.
Which rates should we choose?
For this example, let’s select asthma rates for both sexes age 20 - 64.
asthma_neighb.columns
# Select the neghborhood_id, neighborhood_name, and both sexes with asthma
important_cols = asthma_neighb.columns[[0, 1, 11]]
colnames = {important_cols[0]: 'Neighbid',
important_cols[1] : 'name',
important_cols[2] : 'asthma_pct'}
asthma_rates = asthma_neighb.copy()
asthma_rates = asthma_rates[important_cols]
asthma_rates.rename(columns = colnames, inplace=True)
asthma_rates.head()
Merge Sociodemographic and asthma data#
To examine the relationship between asthma and immigration we will need to merge
socdem_neighbandasthma_rates.The
DataFrames can be merged on neighbourhood id.
# Two datasets are merged based on neighborhood id
asthma_socdem = asthma_rates.merge(socdem_neighb, left_on='Neighbid', right_on='Neighbid')
asthma_socdem.head()
A regression model of asthma on immigration#
Plot the data#
What are the dependent and independent variables?
Does the relationship look linear?
sns.regplot(y = 'asthma_pct', x = 'immigration5', data = asthma_socdem, ci = None);
Describe the relationship between asthma and immigration.
Fit the regression model#
reg_asthmaimm = ols('asthma_pct ~ immigration5', data = asthma_socdem) # setup the model
reg_asthmaimm_fit = reg_asthmaimm.fit() # estimate/fit the model
Statistical summary of the regression model#
reg_asthmaimm_summ = reg_asthmaimm_fit.summary()
reg_asthmaimm_summ.tables[1]
The regression model is the equation:#
The slope indicates that for a 1% increase in immigration in the past 5 years the percentage of asthma cases in a neighbourhood decrease by 0.1597 (approximately 16%).
The y-intercept indicates that when a neighbourhood has 0% immigration the past 5 years then asthma rates are 11%.
Are there any neighbourhoods with 0% immigration in the past 5 years?
asthma_socdem['immigration5'].describe()
The y-intercept in regression models often doesn’t have a sensible interpretation, but is often mathematically important for regression to work well.
Accuracy of the regression model#
reg_asthmaimm_fit.rsquared
plt.scatter(x = reg_asthmaimm_fit.fittedvalues , y = reg_asthmaimm_fit.resid)
plt.axhline(y = 0)
plt.xlabel('fitted values')
plt.ylabel('residuals')
The R-squared statistics indicates a relatively good explanation of the model (quite larger than 0)
The residual plot indicates some important variables are missing, as we can see larger abolute values as fitted values increase (not a random distributed pattern)
Summary#
Therefore, we can conclude that the immigration rate in recent 5 years in a neighborhood is negatively associated with the prevalence of asthma in the neighborhood.
Why not causal relationship?
What is the implication?
Training and testing a model#
Ideally we could assess the accuracy of this linear regression model on a new set of data (i.e., immigration rates in Toronto neighbourhoods in future years.)
But, we don’t have this data.
One trick that data scientists use to fit the model on part of the data (training data) and use the remaining part (testing data) to test the accuracy.
If we only have one data set then the training data can be obtained by randomly selecting rows from the data to fit the regression model, then the remaining rows can be used to test the accuracy of the model.
Splitting a pandas DataFrame by index#
data = {'a' : [1, 2, 3, 4, 5]}
df = pd.DataFrame(data)
df.index
A Boolean array that is True if the index is 0 or 1 and False otherwise.
df.index.isin([0,1])
To create a Boolean series that is False if the index is 0 or 1 and True otherwise we can negate df.index.isin([0,1]) this Boolean series using the ~ operator ~df.index.isin([0,1])
~df.index.isin([0,1])
df[~df.index.isin([0,1])]
Creating training and test data sets from a single dataset#
Step 1:#
split the data into a training set with 75% of the rows.
use the remaining 25% of the data for testing.
np.random.seed(11) # for reproducibility
# randomly select 75% of neighbourhoods
reg_df_train = asthma_socdem.sample(frac = 0.75, replace = False)
# get index of training data
train_index = reg_df_train.index
Exclude indicies from
reg_df_trainusingpandasisinfunction.
# exclude rows in training to define test data
reg_df_test = asthma_socdem[~asthma_socdem.index.isin(train_index)]
print(asthma_socdem.shape)
print(reg_df_train.shape)
print(reg_df_test.shape)
Step 2: Fit the regression model on the training data#
reg_train = ols('asthma_pct ~ immigration5', data = reg_df_train) # setup the model
reg_train_fit = reg_train.fit() # estimate/fit the model
Step 3: Compute predicted (fitted) values using training data#
# use the model fit on the training data to predict asthma rates
# from the test set.
predvalues_train = reg_train_fit.predict(reg_df_train['immigration5'])
Step 4: Evaluate accuracy using root mean-squared error on training data#
Another measure of accuracy of regression models.
Compares observed values of the dependent variable with the predicted values.
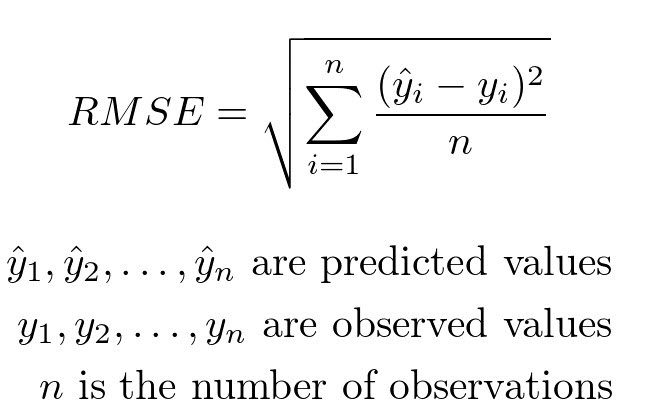
It can be computed using the rmse function from statsmodels.
# Compute root mean-squared error for the training data.
from statsmodels.tools.eval_measures import rmse
rmse(predvalues_train, reg_df_train['asthma_pct'])
The observed asthma rates deviate from the predicted asthma rates in each neighbourhood by 1.4% in the training set.
Is this an acceptable prediction error?
Let’s examine the accuracy of the linear regression model on the test set
Step 5: Evaluate the accuracy of regression model on the test data using root mean-squared error#
Compute predictions using test data
predvalues_test = reg_train_fit.predict(reg_df_test['immigration5'])
Now compute the root mean-squared error for the test data using the model fit on the training data.
rmse(predvalues_test, reg_df_test['asthma_pct'])
Conclusion of data analysis using linear regression model#
The regression model appears to provide an accurate fit the data, although both the scatter plot and plot of residuals indicate that there is a lot of variation in asthma rates in neighbourhoods that have between 10% - 20% immigration.
As the percentage of immigrants to a neighbourhood within the last 5 years increases, the asthma rates will decreases.
Regression analyses on aggregated data such as neighbourhoods can be misleading when compared to non-aggregated data.
Are there other sociaodemographic factors in our data that might effect asthma rates?#
Let’s create a matrix scatter plot using
pairplotin theseabornlibrary.pairplotwill visualize paired relationship between variables in a dataset.
asthma_socdem.columns
# reduce the column for better presentation
to_show = ['asthma_pct','median_income','rented_dwell','immigration5','vismin']
sns.pairplot(asthma_socdem[to_show]);
Let’s consider median income
Fit the regression model on all the data and produce a statistical summary.
reg_asthmaimmunem = ols('asthma_pct ~ immigration5 + median_income', data = asthma_socdem) # setup the model
reg_asthmaimmunem_fit = reg_asthmaimmunem.fit() # estimate/fit the model
reg_asthmaimmunem_summ = reg_asthmaimmunem_fit.summary()
reg_asthmaimmunem_summ.tables[1]
Notice that the slope estimate for
median_incomeis 0, but so is the p-value and range of plausible values.That seems odd. What’s happening?
We can see from the scatter plot that
immigration5andmedian_incomehave a linear relationship. When two variables have a linear relationship multiple linear regression models produce strange results.It’s important that independent variables in a multiple regression model are unrelated.
sns.regplot(y = 'immigration5', x = 'median_income', data = asthma_socdem, ci = None);